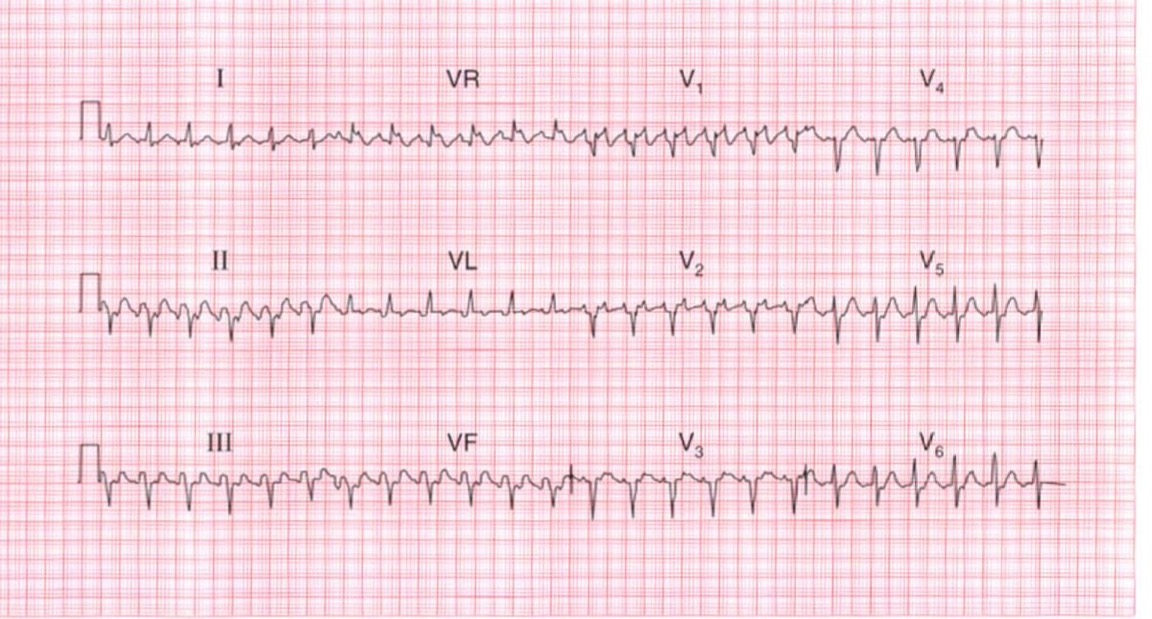
Large Language Models (LLMs) face several unique challenges when interpreting ECG scans, particularly in distinguishing between similar arrhythmias like Atrial Fibrillation and SVT. These challenges include:
- Pattern Recognition Limitations: While LLMs excel at processing textual descriptions, they may struggle with subtle visual patterns in ECG waveforms that human cardiologists can readily identify.
- Context Integration: Different models may weigh various ECG features differently,
leading to varying interpretations. For example:
- Some models might prioritize R-R interval regularity
- Others might focus more on baseline characteristics or P wave morphology
- The presence of noise or artifacts can affect different models in varying ways
- Training Data Bias: Models may be trained on datasets with varying proportions of A-fib and SVT cases, leading to potential bias in their interpretations.
- Feature Extraction Challenges: In cases where the distinguishing features between A-fib and SVT are subtle (like slightly irregular vs regular rhythms), different models may have varying thresholds for what constitutes "irregular" rhythm.
This case study demonstrates these challenges by examining how different interpretations can arise from the same ECG, particularly in distinguishing between Atrial Fibrillation with RVR and SVT, where the key differentiating features can be subtle and open to varying interpretations.